



شکستن مرزها در محاسبات شتابدادهشده و هوش مصنوعی مولد
با پیشرفتهای شگرفی که معماری بلک ول NVIDIA Blackwell Architecture در هوش مصنوعی مولد و محاسبات شتابدادهشده ایجاد میکند، آشنا شوید. Blackwell با تکیه بر نسلهای متوالی از فناوریهای NVIDIA، فصل تازهای را در هوش مصنوعی مولد رقم میزند و عملکرد، بهرهوری، و مقیاسی بیسابقه ارائه میدهد. معماری Blackwell انویدیا با معرفی پیشرفتهای تحولآفرین برای هوش مصنوعی مولد و محاسبات شتابدادهشده، مرکز دادهها را وارد عصری جدید میکند. استفاده از موتور تبدیل نسل دوم و رابطهای سریعتر و پهنای بیشتر NVIDIA NVLink عملکردی بسیار بالاتر نسبت به نسل قبلی این معماری ارائه میدهد.
بهعلاوه، پیشرفتهای جدید در فناوری NVIDIA Confidential Computing سطح امنیت را برای استنتاج بلادرنگ هوش مصنوعی مولد در مقیاس بزرگ بدون کاهش عملکرد افزایش میدهد. همچنین موتور کاهش فشردهسازی جدید Blackwell به همراه کتابخانههای Spark RAPIDS عملکرد بینظیری در پایگاهدادهها برای کاربردهای تحلیل داده فراهم میکند. این نوآوریها که بر پایهی چندین نسل از فناوریهای محاسبات شتابدادهشده انویدیا بنا شدهاند، عملکرد، کارایی و مقیاسپذیری بیسابقهای را در نسل جدید هوش مصنوعی مولد تعریف میکنند.
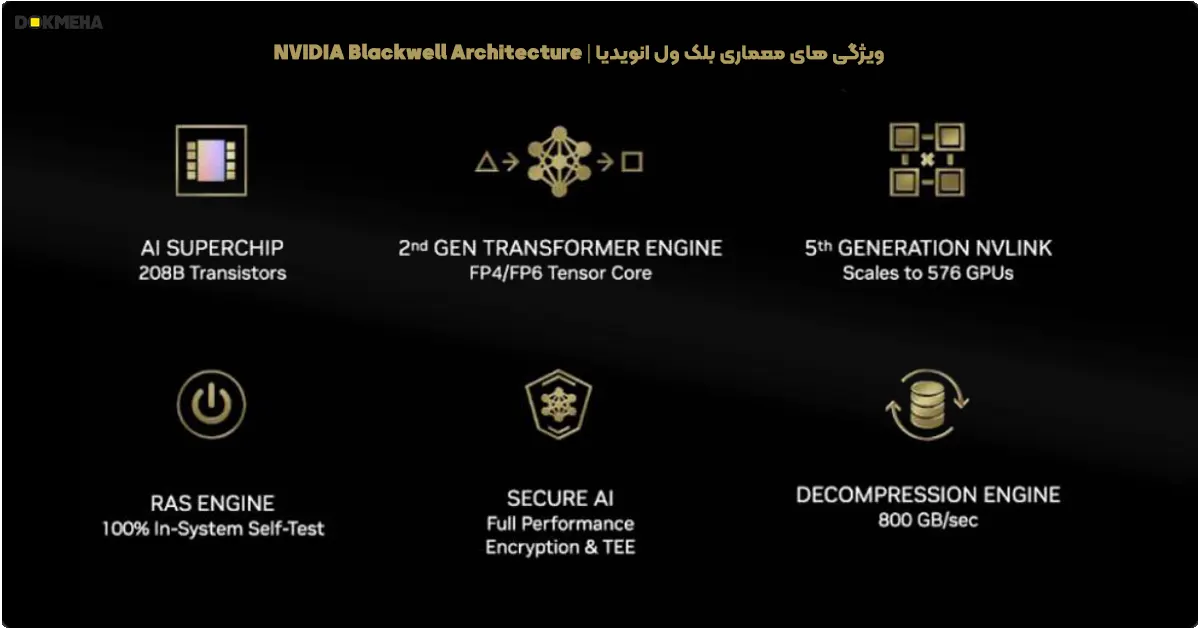
نگاهی به نوآوریهای تکنولوژیکی معماری بلک ول Blackwell انودیا
کلاس جدیدی از سوپرچیپهای هوش مصنوعی
پردازندههای گرافیکی با معماری Blackwell با داشتن ۲۰۸ میلیارد ترانزیستور، یعنی بیش از ۲.۵ برابر تعداد ترانزیستورهای موجود در پردازندههای گرافیکی NVIDIA Hopper و با بهرهگیری از فرآیند 4NP شرکت TSMC که بهطور ویژه برای NVIDIA بهینهسازی شده است، Blackwell به بزرگترین پردازنده گرافیکی ساختهشده تاکنون تبدیل شده است. این تراشه به بالاترین توان محاسباتی در یک چیپ واحد دست یافته و عملکردی بالغ بر ۲۰ پتا فلاپس ارائه میدهد. (فناوری TSMC 4NP یک فرآیند ساخت نیمههادی سفارشی است که توسط شرکت TSMC (شرکت تولید مدارهای مجتمع تایوان) برای تولید تراشههای پیشرفته مانند معماری Blackwell انویدیا استفاده میشود. این فناوری با طراحیهای بسیار فشرده و بهینهسازیشده، عملکرد و کارایی بالاتری را فراهم میکند و تعداد ترانزیستورها را تا مقیاس ۲۰۸ میلیارد ترانزیستور در هر تراشه افزایش میدهد.)
این معماری با ترکیب دو قالب یا دو دای محدود به رتیکل (Reticle-limited die) در یک پردازنده گرافیکی یکپارچه، توان محاسباتی چشمگیری را به دست آورده است. هرکدام از این دو قالب به بزرگترین ابعاد ممکن در حد نهایی ماسک ریختهگری ساخته شدهاند. این دو قالب با استفاده از رابط NVIDIA High-Bandwidth Interface (NV-HBI) با پهنای باند ۱۰ ترابایت بر ثانیه به یکدیگر متصل شدهاند و یک پردازنده گرافیکی یکپارچه و همبسته ایجاد میکنند. معماری Blackwell فراتر از تراشهای با نرخ عملیات محاسباتی بالاست. این معماری از اکوسیستم غنی توسعه ابزارهای NVIDIA، کتابخانههای CUDA-X™، بیش از چهار میلیون توسعهدهنده و بیش از ۳۰۰۰ برنامه که عملکرد را در هزاران نود گسترش میدهند، بهرهمند است.
موتور تبدیل نسل دوم Second-Generation Transformer Engine
Blackwell با معرفی موتور ترنسفورمر نسل دوم، جهشی جدید در بهبود سرعت پردازش و آموزش مدلهای زبان بزرگ (LLM) و مدلهای Mixture-of-Experts (MoE) ایجاد کرده است. این موتور جدید از فناوری اختصاصی Blackwell Tensor Core به همراه نوآوریهای TensorRT-LLM و پلتفرم Nemo استفاده میکند تا قابلیت استنتاج و آموزش مدلهای پیچیده را به شکل بیسابقهای تسریع کند.
برای تقویت استنتاج مدلهای بزرگ MoE، هستههای Tensor در Blackwell از دقتهای جدید از جمله قالبهای میکروسکیلینگ تعریفشده توسط جامعه استفاده میکنند تا دقت بالا و توان عملیاتی بهتری ارائه دهند. موتور ترنسفورمر Blackwell با استفاده از الگوریتمهای مدیریت محدوده دینامیکی پیشرفته و تکنیکهای مقیاسبندی ریزدانه، به نام مقیاسبندی میکرو-تنظیم، عملکرد و دقت را بهینهسازی کرده و از FP4 در هوش مصنوعی پشتیبانی میکند. این امر عملکرد را با هسته FP4 Blackwell دو برابر میکند و پهنای باند پارامترها را به حافظه HBM دو برابر کرده و اندازه مدلهای نسل بعدی را برای هر پردازنده گرافیکی دو برابر میسازد. فناوری TensorRT-LLM نوآوریهای بیشتری مانند کوانتسازی به دقت ۴ بیت و کرنلهای سفارشی با نقشهبرداری از موازیسازی خبره را ارائه میدهد. این ویژگیها استنتاج لحظهای مدلهای MoE را با سختافزار و انرژی کمتر و هزینه کمتر ممکن میسازد.
برای آموزش، موتور ترنسفورمر نسل دوم با استفاده از چارچوب Nemo و Megatron-Core از تکنیکهای جدید موازیسازی خبره بهره میبرد که با سایر روشهای موازیسازی و NVLink نسل پنجم ترکیب میشوند تا عملکرد مدل را بهطور بیسابقهای بهبود بخشند. فرمتهای دقت پایینتر، امکان شتاب بیشتر در آموزش مدلهای بزرگمقیاس را فراهم میکنند. با موتور ترنسفورمر نسل دوم Blackwell، سازمانها میتوانند مدلهای MoE پیشرفته را با اقتصادیترین روشها پیادهسازی کرده و با استفاده از هوش مصنوعی مولد، بهینهسازی کسبوکار خود را ممکن سازند. NVIDIA Blackwell دور جدیدی از مدلهای MoE را ممکن میسازد و از آموزش و استنتاج لحظهای مدلهایی با بیش از ۱۰ تریلیون پارامتر پشتیبانی میکند.
محاسبات امن با عملکرد بالا و هوش مصنوعی امن در معماری بلک ول Blackwell
هوش مصنوعی مولد، فرصتهای زیادی برای کسبوکارها فراهم میکند؛ از بهینهسازی درآمد و ارائه بینشهای تجاری گرفته تا تولید محتوای مولد. با این حال، پذیرش این فناوری برای کسبوکارهایی که نیاز به آموزش مدلهای بزرگ روی دادههای خصوصی دارند و ممکن است تحت مقررات حریم خصوصی یا دارای اطلاعات محرمانه باشند، چالشبرانگیز است. قابلیتهای NVIDIA Confidential Computing محدوده محیط اجرای قابلاعتماد (TEE) را فراتر از CPUها به GPUها گسترش داده است. رایانش محرمانه در NVIDIA Blackwell به گونهای طراحی شده که بالاترین سطح امنیت و حفاظتهای مبتنی بر شواهد (attestable) را برای مدلهای زبانی بزرگ (LLMs) و سایر دادههای حساس ارائه کند. Blackwell اولین پردازنده گرافیکی با قابلیت TEE-I/O در صنعت را معرفی میکند، که همراه با میزبانیهای سازگار با TEE-I/O و محافظتهای درونخطی در NVLink، بالاترین سطح محرمانگی و یکپارچگی را فراهم میآورد.
رایانش محرمانه یا Confidential Computing در Blackwell تقریباً همان عملکرد از نظر کارایی را بهصورت رمزگذاریشده و غیررمزگذاریشده ارائه میدهد. حالا مشتریان میتوانند حتی بزرگترین مدلها را به روشی امن و با عملکرد بالا محافظت کرده و همچنین از مالکیت فکری (IP) هوش مصنوعی محافظت کنند. این امکان، آموزش، استنتاج و یادگیری فدرال هوش مصنوعی محرمانه را بهطور امن ممکن میسازد.
نسل پنجم NVLink و NVLink Switch
برای بهرهبرداری کامل از توان رایانش در مقیاس اگزافلاپ و مدلهای هوش مصنوعی چندتریلیونپارامتری، نیاز به ارتباط سریع و یکپارچه بین تمامی پردازندههای گرافیکی در یک کلاستر سروری است. نسل پنجم NVLink با استفاده از ASIC سوئیچ NVLink و سوئیچهای طراحیشده بر پایه آن، تا ۵۷۶ پردازنده گرافیکی را برای شتابدهی به عملکرد مدلهای هوش مصنوعی چندتریلیونپارامتری مقیاسپذیر میکند و دو برابر پهنای باند NVLink نسل چهارم را در NVIDIA Hopper ارائه میدهد. پردازندههای گرافیکی Blackwell با استفاده از جفتهای دیفرانسیلی در هر جهت، همانند Hopper، پهنای باند لینکها را دو برابر کرده و به ۵۰ گیگابایت بر ثانیه در هر جهت میرسانند.
پردازندههای گرافیکی Blackwell مجهز به ۱۸ لینک NVLink نسل پنجم هستند که در مجموع پهنای باند ۱.۸ ترابایت بر ثانیه، یا ۹۰۰ گیگابایت بر ثانیه در هر جهت، را فراهم میکنند. این پهنای باند ۱.۸ ترابایت بر ثانیهای بیش از ۱۴ برابر پهنای باند PCIe Gen5 است و امکان ارتباط با سرعت بالا را برای پیچیدهترین مدلهای بزرگ فراهم میکند. این سرعت انتقال، معادل هفت پتابایت داده در هر ساعت از یک GPU است و قادر است بیشتر از کل پهنای باند اینترنت را تنها با استفاده از ۱۱ پردازنده گرافیکی Blackwell پردازش کند.
سوئیچ NVIDIA NVLink پهنای باند ۱۳۰ ترابایت بر ثانیه را در یک دامنه NVLink با ۷۲ پردازنده گرافیکی (NVL72) برای موازیسازی مدلها فراهم میکند و با بهرهوری پهنای باند ۴ برابری از طریق پشتیبانی از SHARP™ FP8، امکانپذیر میسازد. ترکیب NVLink و NVLink Switch امکان ارتباط بین سرورهای متعدد با همان پهنای باند ۱.۸ ترابایت بر ثانیه را فراهم میکند و این ترکیب به کلاسترهای چندسروری امکان میدهد که ارتباطات پردازندههای گرافیکی را در تعادل با محاسبات افزایشیافته مقیاس دهند.
سوئیچ NVLink همراه با NVIDIA Unified Fabric Manager (UFM®) مدیریت پیشرفته و آزمایششده در تولید برای این زیرساخت محاسباتی را فراهم میآورد.
موتور کاهش فشرده سازی Decompression در Blackwell
تحلیل دادهها و جریانهای کاری پایگاههای داده که معمولاً بر پردازشگرهای CPU متکی هستند، کند و پرهزینه بودهاند. علم داده شتابدهی شده میتواند به طرز چشمگیری عملکرد تحلیلهای سرتاسری را بهبود داده، سرعت دستیابی به نتایج را افزایش دهد و هزینهها را کاهش دهد. پایگاههای داده مانند Apache Spark نقش مهمی در پردازش و تحلیل حجم بالای دادهها برای تحلیل دادهها ایفا میکنند. موتور Decompression اختصاصی جدید Blackwell قادر است دادهها را با سرعتی تا ۸۰۰ گیگابایت بر ثانیه از حالت فشرده خارج کند و با بهرهگیری از پهنای باند ۸ ترابایت بر ثانیهای حافظه HBM3e در یک GPU از GB200 و ارتباط سریع NVLink-C2C (ارتباط چیپ به چیپ) پردازنده Grace، کل خط لوله جستجوهای پایگاه داده را به سریعترین سطح برای تحلیل دادهها و علم داده میرساند. این موتور، با پشتیبانی از جدیدترین فرمتهای فشردهسازی از جمله LZ4، Snappy، و Deflate، عملکردی ۱۸ برابر سریعتر نسبت به CPUها و ۶ برابر سریعتر از پردازندههای گرافیکی NVIDIA H100 Tensor Core در بنچمارکهای جستجو ارائه میدهد.
موتور RAS در معماری بلک ول Blackwell
معماری Blackwell از طریق افزودن موتور مخصوص قابلیت اطمینان، دسترسپذیری، و سرویسدهی (Reliability, Availability, Serviceability – RAS) به مقاومسازی هوشمند مجهز شده است که به شناسایی خطاهای بالقوه از مراحل ابتدایی پرداخته و به این ترتیب زمان خرابی را به حداقل میرساند. قابلیتهای مدیریت پیشبینی مبتنی بر هوش مصنوعی انویدیا، به طور پیوسته هزاران دادهی مربوط به سلامت سختافزار و نرمافزار را برای شناسایی و ممانعت از منابع احتمالی خرابی و ناکارآمدی پایش میکنند و این امکان را فراهم میآورند تا با هوشمندی، زمان و هزینههای محاسباتی کاهش یابد.
موتور RAS اطلاعات تشخیصی عمیقی ارائه میدهد که میتواند مشکلات احتمالی را شناسایی و به برنامهریزی برای نگهداری کمک کند. این موتور با شناسایی سریع منبع مشکلات، زمان پاسخدهی را کاهش داده و با تسهیل راهکارهای کارآمد، زمان خرابی را به حداقل میرساند. مدیران سیستم میتوانند منابع محاسباتی را تنظیم کرده و استراتژیهای بهینهسازی ذخیرهسازی را برای تداوم عملیات آموزشی در مقیاس بزرگ به کار بگیرند. اگر موتور RAS تشخیص دهد که نیاز به تعویض یک قطعه وجود دارد، ظرفیت پشتیبان فعال میشود تا اطمینان حاصل شود که کار بدون افت عملکرد به موقع به پایان میرسد و تعویض قطعات سختافزاری مورد نیاز به گونهای زمانبندی میشود که از بروز خرابیهای برنامهریزی نشده جلوگیری شود.
نمونه استفاده شده از معماری بلک ول Blackwell در آموزش مدلهای تریلیون پارامتری است که بهطور آنی با NVIDIA GB200 NVL72 می توانید آن را باز کنید، NVIDIA GB200 NVL72 با اتصال ۳۶ سوپرچیپ Grace Blackwell و ۳۶ پردازنده Grace و ۷۲ پردازنده گرافیکی Blackwell در یک طراحی مقیاس رک، ارائه میشود. GB200 NVL72 یک راهحل با خنکسازی مایع است که دارای دامنه NVLink ۷۲-GPU است و بهعنوان یک GPU بزرگ واحد عمل میکند—و ۳۰ برابر سریعتر از قبل، استنباط آنی برای مدلهای زبان بزرگ با تریلیون پارامتر را ارائه میدهد.
