



NVIDIA GB200 NVL72 آموزش تریلیون پارامتر LLM و استنتاج بلادرنگ را ارائه می دهد.
علاقه به مدل های تریلیون پارامتری چیست؟ ما امروزه بسیاری از موارد استفاده را می شناسیم و علاقه به این مدلها به دلیل ظرفیت بالاتر آنها در حال افزایش است که شامل موارد زیر میشود:
- پردازش زبان طبیعی: وظایفی مانند ترجمه، پاسخ به سوالات، خلاصهسازی و روانسازی متن.
- حفظ زمینه و توانایی مکالمه بلندمدت: توانایی مدل در نگهداری اطلاعات طولانیمدت و مکالمات پیچیده.
- کاربردهای چندمدلی: ترکیب زبان، بینایی و گفتار.
- کاربردهای خلاقانه: مانند داستاننویسی، تولید شعر و تولید کد.
- کاربردهای علمی: از جمله پیشبینی تاخوردگی پروتئین و کشف دارو.
- شخصیسازی: با قابلیت ایجاد شخصیتی پایدار و به خاطر سپردن زمینه کاربر.
مزایای این مدلها بسیار زیاد است، اما آموزش و پیادهسازی مدلهای بزرگ میتواند بسیار پرهزینه و نیازمند منابع فراوان باشد. سیستمهایی که از نظر محاسباتی کارآمد، از نظر هزینه بهصرفه و از نظر انرژی بهینه هستند و توانایی ارائه استنتاج در زمان واقعی را دارند، برای استفاده گسترده از این مدلها ضروری خواهند بود. مدل NVIDIA GB200 NVL72 نمونهای از چنین سیستمی است که برای این کار مناسب میباشد.
به عنوان مثال، مدلهای “ترکیب کارشناسان” (Mixture of Experts) MoE را در نظر بگیرید. این مدلها به توزیع بار محاسباتی بین چندین کارشناس کمک میکنند و با استفاده از چندین GPU از طریق موازیسازی مدل و موازیسازی خطوط، به آموزش پرداخته و سیستم را کارآمدتر میکنند.
با این حال، یک سطح جدید از محاسبات موازی، حافظه با سرعت بالا و ارتباطات با کارایی بالا میتواند به خوشههای GPU کمک کند تا این چالش فنی را قابل مدیریت کنند. معماری NVIDIA GB200 NVL72 در مقیاس رک به این هدف دست یافته است، که جزئیات آن را در این پست توضیح خواهیم داد.
طراحی در مقیاس رک برای یک ابررایانه هوش مصنوعی Exascale
قلب سیستم GB200 NVL72، تراشه NVIDIA GB200 Grace Blackwell Superchip است که دو GPU قدرتمند NVIDIA Blackwell Tensor Core و یک CPU از نوع NVIDIA Grace را با استفاده از رابط NVLink-Chip-to-Chip (C2C) به هم متصل میکند و پهنای باند دوطرفهای معادل ۹۰۰ گیگابایت بر ثانیه ارائه میدهد. با استفاده از NVLink-C2C، برنامهها به یک فضای حافظه یکپارچه دسترسی هماهنگ دارند. این ویژگی باعث سادهتر شدن برنامهنویسی و پشتیبانی از نیازهای حافظه بزرگ مدلهای زبانی با تریلیون پارامتر، مدلهای ترنسفورمر برای وظایف چندمدلی، مدلهای شبیهسازی در مقیاس بزرگ، و مدلهای تولیدی برای دادههای سهبعدی میشود.
سینی محاسباتی GB200 بر اساس طراحی جدید NVIDIA MGX ساخته شده است و شامل دو CPU از نوع Grace و چهار GPU از نوع Blackwell میباشد. این سینی محاسباتی دارای صفحات سرد و اتصالات برای خنکسازی مایع، پشتیبانی از PCIe نسل ۶ برای شبکهسازی پرسرعت، و کانکتورهای NVLink برای کارتریج کابل NVLink است. سینی محاسباتی GB200 عملکردی معادل ۸۰ پتافلاپس در زمینه هوش مصنوعی و ۱.۷ ترابایت حافظه سریع ارائه میدهد.

بزرگترین مسائل نیازمند تعداد کافی از GPUهای پیشرفته Blackwell هستند تا بهصورت موازی و کارآمد عمل کنند؛ بنابراین باید با پهنای باند بالا و تأخیر کم ارتباط برقرار کرده و بهطور مداوم فعال بمانند. سیستم در مقیاس رک GB200 NVL72 با استفاده از سیستم سوئیچ NVIDIA NVLink و تعداد ۹ سینی سوئیچ NVLink، کارایی مدلهای موازی را برای ۱۸ نود محاسباتی تسهیل میکند. همچنین، کارتریجهای کابل برای اتصال GPUها و سوئیچها به کار گرفته میشوند تا ارتباط مؤثر میان آنها برقرار شود.
مدلهای NVIDIA GB200 NVL36 و NVL72
سیستم GB200 از ۳۶ و ۷۲ پردازنده گرافیکی GPU در دامنههای NVLink پشتیبانی میکند. هر رک شامل ۱۸ نود محاسباتی مبتنی بر طراحی مرجع MGX و سیستم سوئیچ NVLink است. پیکربندی GB200 NVL36 دارای 36x GPU در یک رک و ۹ نود محاسباتی دوگانه GB200 میباشد. مدل GB200 NVL72 به صورت 72x GPU در یک رک با ۱۸ نود محاسباتی دوگانه GB200 یا 72x GPU در دو رک با ۱۸ نود محاسباتی تکگانه GB200 تنظیم شده است.
مدل GB200 NVL72 بهصورت متراکم GPUها را با استفاده از کارتریج کابل مسی برای سادگی عملیاتی به هم متصل میکند. همچنین از طراحی سیستم خنککننده مایع استفاده میکند که ۲۵ برابر هزینه و مصرف انرژی کمتری دارد.

سیستم سوئیچ NVLink و NVLink نسل پنجم
NVIDIA GB200 NVL72 نسل پنجم NVLink را معرفی می کند که تا ۵۷۶ پردازنده گرافیکی را در یک دامنه NVLink با بیش از پتابایت بر ثانیه 1PB/s پهنای باند کل و ۲۴۰ ترابایت حافظه سریع متصل می کند. هر سینی سوئیچ NVLink دارای ۱۴۴ پورت NVLink با سرعت ۱۰۰ گیگابایت است، بنابراین ۹ سوئیچ بهطور کامل هر یک از ۱۸ پورت NVLink بر روی ۷۲ عدد GPU Blackwell را متصل میکنند.
توان عملیاتی دوطرفه ۱.۸ ترابایت بر ثانیه برای هر GPU، بیش از ۱۴ برابر پهنای باند PCIe نسل ۵ است و ارتباطات پرسرعت و بیوقفهای را برای مدلهای پیچیده امروزی فراهم میکند.

NVLink در طول نسل ها
نوآوری پیشرو NVIDIA در زمینه SerDes با سرعت بالا و مصرف کم، پیشرفت ارتباطات GPU به GPU را به جلو برده است و با معرفی NVLink برای تسریع ارتباطات چند GPU با سرعت بالا آغاز شده است. پهنای باند ارتباطات GPU به GPU در NVLink برابر با ۱.۸ ترابایت بر ثانیه است، که ۱۴ برابر پهنای باند PCIe میباشد. نسل پنجم NVLink با سرعت ۱۶۰ گیگابایت بر ثانیه، ۱۲ برابر سریعتر از نسل اول است که در سال ۲۰۱۴ معرفی شد. ارتباطات NVLink بین GPUها نقش مهمی در مقیاسدهی عملکرد چند GPU در هوش مصنوعی و محاسبات با کارایی بالا (HPC) داشته است.
پیشرفت در پهنای باند GPU به همراه گسترش نمایی اندازه دامنه NVLink، پهنای باند کل یک دامنه NVLink را از سال ۲۰۱۴ به میزان ۹۰۰ برابر افزایش داده است و برای یک دامنه NVLink با ۵۷۶ GPU Blackwell به ۱ پتابایت بر ثانیه رسیده است.
موارد استفاده GB200 NVL72 و نتایج عملکرد
توان محاسباتی و قابلیتهای ارتباطی GB200 NVL72 بینظیر است و چالشهای بزرگ در حوزه هوش مصنوعی و محاسبات با کارایی بالا (HPC) را به دسترس عملی نزدیک میکند.
آموزش هوش مصنوعی
مدل GB200 شامل موتور ترانسفورمر نسل دوم سریعتر با دقت FP8 است. این مدل با استفاده از ۳۲ هزار GB200 NVL72، عملکرد آموزش را برای مدلهای زبانی بزرگ مانند GPT-MoE-1.8T چهار برابر سریعتر از تعداد مشابه GPUهای NVIDIA H100 ارائه میدهد.
استنتاج هوش مصنوعی
مدل GB200 قابلیتهای پیشرفتهای را همراه با موتور ترانسفورمر نسل دوم ارائه میدهد که باعث تسریع بارهای کاری استنتاج مدلهای زبانی بزرگ (LLM) میشود. این مدل ۳۰ برابر افزایش سرعت برای کاربردهای پردازش فشرده مانند GPT-MoE با ۱.۸ تریلیون پارامتر نسبت به نسل قبلی H100 ارائه میدهد. این پیشرفت با نسل جدید Tensor Cores که دقت FP4 و مزایای بسیاری همراه با نسل پنجم NVLink را معرفی میکند، امکانپذیر شده است.
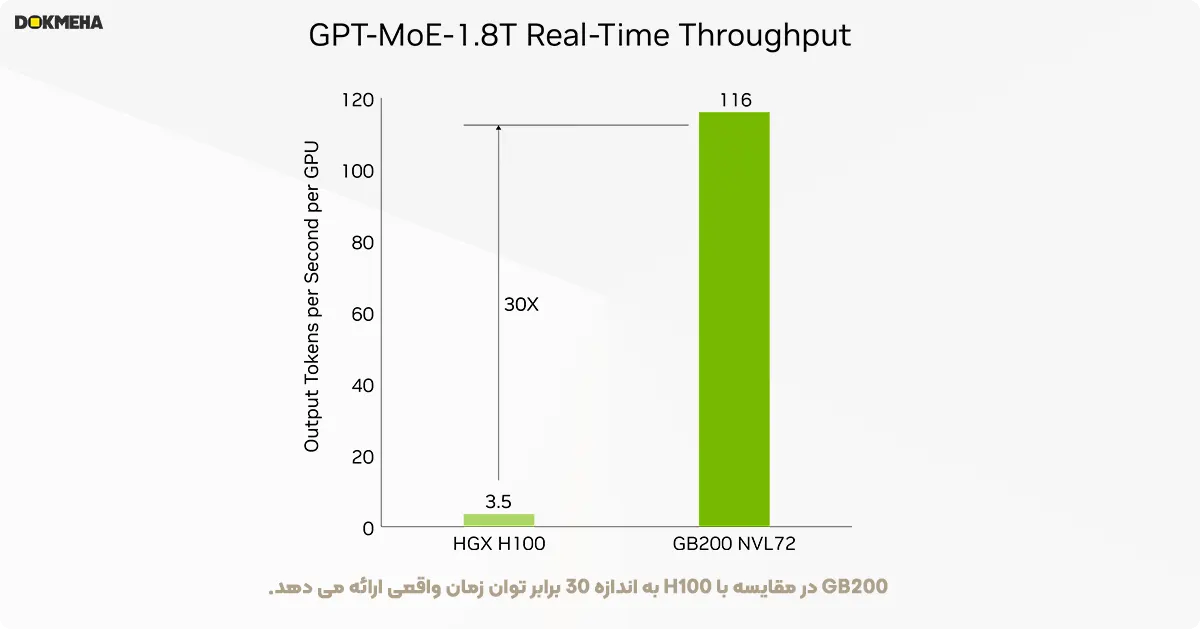
این مقایسه به وضوح نشان میدهد که GB200 با استفاده از خنککننده مایع و معماری پیشرفتهتر NVLink NVL72 قادر به ارائه عملکرد به مراتب بهتر در شرایط پردازش واقعی و تأخیر کمتر در استنتاج مدلهای هوش مصنوعی است.
پردازش داده ها
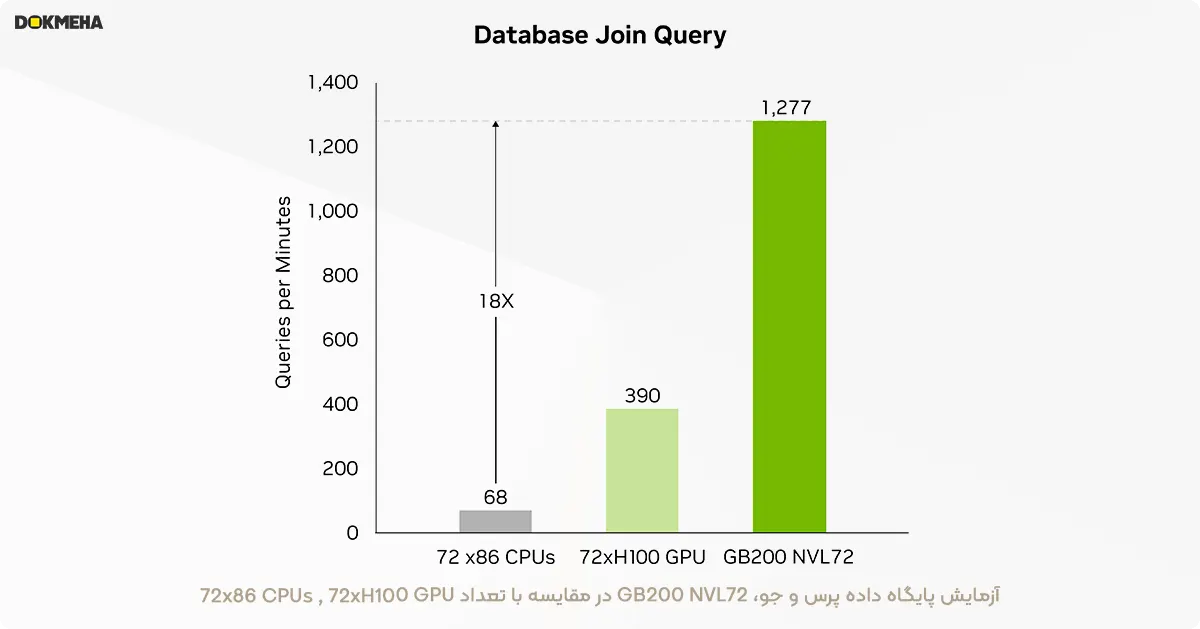
تحلیل دادههای بزرگ به سازمانها کمک میکند تا با کشف بینشها تصمیمات بهتری بگیرند. سازمانها به طور مداوم دادهها را در مقیاس بزرگ تولید میکنند و از تکنیکهای فشردهسازی مختلف برای کاهش تنگناها و صرفهجویی در هزینههای ذخیرهسازی استفاده میکنند. برای پردازش کارآمد این دادهها بر روی پردازندههای گرافیکی، معماری Blackwell یک موتور سختافزاری برای رفع فشردهسازی دادهها معرفی کرده است که میتواند دادههای فشرده را در مقیاس وسیع به صورت بومی رفع فشردهسازی کند و کل فرایند تجزیه و تحلیل را تسریع کند. این موتور از فرمتهای فشردهسازی LZ4، Deflate و Snappy به صورت بومی پشتیبانی میکند.
این موتور عملکرد عملیات محدود به حافظه را تسریع میکند و تا ۸۰۰ گیگابایت بر ثانیه عملکرد ارائه میدهد. این ویژگی باعث میشود که Grace Blackwell تا ۱۸ برابر سریعتر از پردازندههای مرکزی (Sapphire Rapids) و ۶ برابر سریعتر از پردازندههای گرافیکی NVIDIA H100 Tensor Core در بنچمارکهای پرسوجو عمل کند.
با پهنای باند حافظه خیرهکننده ۸ ترابایت بر ثانیه و NVLink-Chip-to-Chip (C2C) پرسرعت پردازنده Grace، این موتور فرایند کامل پرسوجوهای پایگاه داده را تسریع میکند. این امر منجر به عملکرد برتر در کاربردهای تحلیل داده و علم داده میشود و به سازمانها امکان میدهد تا با کاهش هزینهها به سرعت به بینشهای مورد نیاز دست یابند.
شبیه سازی های مبتنی بر فیزیک
شبیهسازیهای مبتنی بر فیزیک همچنان اساس طراحی و توسعه محصولات هستند. از هواپیما و قطار گرفته تا پلها، تراشههای سیلیکونی و حتی داروها، تست و بهبود محصولات از طریق شبیهسازی میتواند میلیاردها دلار صرفهجویی کند.
مدارهای مجتمع خاص کاربرد (ASIC) تقریباً به طور کامل بر روی پردازندههای مرکزی طراحی میشوند، که شامل یک جریان کاری طولانی و پیچیده برای تحلیل آنالوگ به منظور شناسایی ولتاژها و جریانها است. شبیهساز Cadence SpectreX یکی از مثالهای حلکنندهها در این زمینه است. پیشبینی میشود که شبیهسازیهای مدار با SpectreX روی یک ابرتراشه GB200 Grace Blackwell—که پردازندههای گرافیکی Blackwell و پردازندههای Grace را به هم متصل میکند—تا ۱۳ برابر سریعتر از پردازندههای مرکزی سنتی اجرا شود.
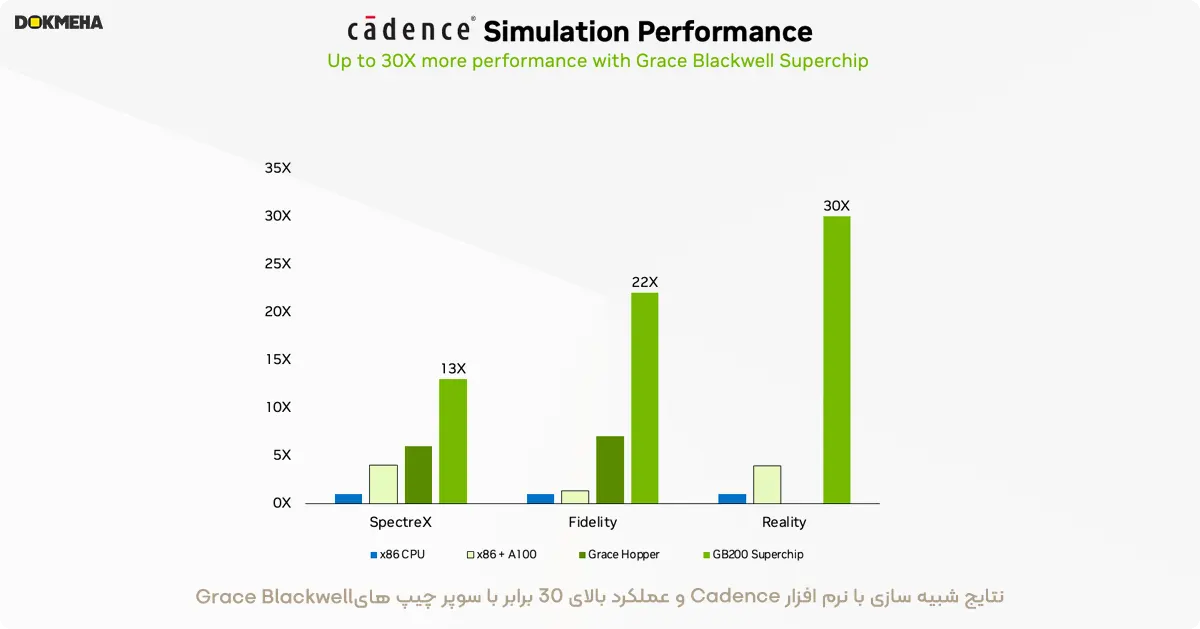
در دو سال گذشته، صنعت به طور فزایندهای به دینامیک سیالات محاسباتی (CFD) با شتابدهندههای GPU به عنوان ابزاری کلیدی روی آورده است. مهندسان و طراحان تجهیزات از آن برای مطالعه و پیشبینی رفتار طراحیهای خود استفاده میکنند. شبیهسازیهای Cadence Fidelity در سیستمهای GB200 پیشبینی میشود که تا ۲۲ برابر سریعتر از سیستمهای سنتی مبتنی بر CPU اجرا شوند.
ما مشتاقیم که امکانات Cadence Fidelity را روی GB200 NVL72 بررسی کنیم. با قابلیت مقیاسپذیری موازی و ۳۰ ترابایت حافظه در هر رک، هدف ما این است که جزئیات جریانهایی را به دست آوریم که هرگز پیش از این ثبت نشدهاند.
خلاصه
برای جمعبندی، طراحی رک مقیاس GB200 NVL72 را مرور کردیم و به ویژه از قابلیت منحصر به فرد آن برای اتصال ۷۲ پردازنده گرافیکی Blackwell بر روی یک دامنه NVIDIA NVLink آگاه شدیم. این قابلیت، بار ارتباطات را که هنگام مقیاسبندی در شبکههای سنتی تجربه میشود، کاهش میدهد. به این ترتیب، استنتاج در زمان واقعی برای یک مدل زبان بزرگ MoE با ۱.۸ تریلیون پارامتر امکانپذیر است و آموزش آن مدل ۴ برابر سریعتر است.
عملکرد ۷۲ پردازنده گرافیکی Blackwell متصل به NVLink با ۳۰ ترابایت حافظه یکپارچه بر روی یک ساختار محاسباتی با سرعت ۱۳۰ ترابایت در ثانیه، یک سوپرکامپیوتر AI با توان محاسباتی اگزافلاپ در یک رک ایجاد میکند. این همان NVIDIA GB200 NVL72 است.
منبع: بلاگ انودیا