



تنسور چیست؟
تنسور در ریاضیات و علوم کامپیوتر، یک ساختار دادهای است که برای نمایش دادهها در چندین بعد استفاده میشود. یک تنسور میتواند به سادگی یک اسکالر (یک عدد)، یک بردار (لیستی از اعداد)، یا ماتریس (آرایهای دوبعدی از اعداد) باشد، اما میتواند ابعاد بیشتری نیز داشته باشد (مانند آرایههای چندبعدی).
در زمینه محاسبات عددی و هوش مصنوعی، تنسورها ابزارهای کلیدی برای نمایش دادهها و انجام عملیات محاسباتی پیچیده هستند. به عنوان مثال، در شبکههای عصبی عمیق، دادهها به صورت تانسورها ذخیره و پردازش میشوند.
هستههای تنسور (Tensor Cores) چیست؟
Tensor Cores نوعی هستهی پردازشی تخصصی هستند که توسط NVIDIA در معماریهای پردازندههای گرافیکی خود معرفی شدهاند. این هستهها برای انجام محاسبات ماتریسی با سرعت بسیار بالا طراحی شدهاند، که بخش کلیدی بسیاری از الگوریتمهای یادگیری عمیق (Deep Learning) است. هستههای تنسور میتوانند عملیات ضرب ماتریس-ماتریس (Matrix-Multiply-Accumulate) را به طور موازی و با دقت بالا انجام دهند، که معمولاً در آموزش و استنتاج شبکههای عصبی به کار میرود.
هستههای تنسور NVIDIA
شتاب بینظیر برای هوش مصنوعی مولد (Generative AI)
هستههای تنسور با استفاده از پردازش Mixed-Precision (دقت ترکیبی)، محاسبات را به صورت پویا بهینه میکنند تا بهرهوری را افزایش دهند، در حالی که دقت و امنیت را حفظ میکنند. نسل جدید این هستهها سریعتر از همیشه در طیف گستردهای از وظایف مرتبط با هوش مصنوعی و پردازشهای محاسباتی با کارایی بالا (HPC) عمل میکنند.
- مزایای نسل پنجم:
- ۴ برابر افزایش سرعت در آموزش مدلهای هوش مصنوعی عظیم با تریلیونها پارامتر.
- ۳۰ برابر بهبود عملکرد در استنتاج (Inference).
- شتابدهی به تمامی وظایف مرتبط با کارخانههای هوش مصنوعی مدرن.
انقلاب در آموزش هوش مصنوعی (Revolutionary AI Training)
آموزش مدلهای عظیم با چندین تریلیون پارامتر در دقت FP16 ممکن است ماهها طول بکشد.
- هستههای تنسور NVIDIA با استفاده از دقت کاهشیافته FP8 در موتور Transformer، عملکردی تا ۱۰ برابر سریعتر ارائه میدهند.
- با پشتیبانی از فریمورکهای بومی از طریق کتابخانههای CUDA-X™، پیادهسازی بهطور خودکار انجام شده و زمان آموزش تا رسیدن به نتیجه کاهش مییابد، در حالی که دقت همچنان حفظ میشود.
 تحولی در استنتاج (Breakthrough Inference)
تحولی در استنتاج (Breakthrough Inference)
یکی از مهمترین الزامات در استنتاج، دستیابی به تأخیر کم با بهرهوری بالا است.
- موتور نسل دوم Transformer در معماری Blackwell عملکردی استثنایی ارائه میدهد و توانایی تسریع مدلهای چندین تریلیون پارامتری را دارد.
- هستههای تنسور NVIDIA، عملکرد بیرقیبی در بنچمارکهای صنعتی MLPerf برای استنتاج کسب کردهاند.
 HPC پیشرفته (Advanced HPC)
HPC پیشرفته (Advanced HPC)
محاسبات با کارایی بالا (HPC) یکی از ارکان اساسی علوم مدرن است.
- دانشمندان از شبیهسازیها برای کشف دارو، تحلیل فیزیکی منابع انرژی و پیشبینی الگوهای آبوهوایی استفاده میکنند.
- هستههای تنسور NVIDIA با پشتیبانی از طیف گستردهای از دقتها، از جمله FP64، محاسبات علمی و شبیه سازیها را با بالاترین دقت شتاب میبخشند.
- HPC SDK ابزارها و کتابخانههای ضروری برای توسعه برنامههای HPC روی پلتفرم NVIDIA را فراهم میکند.
پلتفرم کامل HPC و AI با هستههای تانسور
هستههای تنسور NVIDIA، ستون اصلی یک راهحل جامع مرکز داده هستند که سختافزار، شبکه، نرمافزار، کتابخانهها، و مدلهای بهینهسازیشده را یکپارچه میکند.
- این پلتفرم به محققان اجازه میدهد نتایج واقعی را بهسرعت ارائه دهند و راهحلها را در مقیاس گسترده پیادهسازی کنند.
نسلهای Tensor Cores در کارتهای گرافیک NVIDIA
NVIDIA در هر نسل از معماریهای پردازندههای گرافیکی خود بهبودهایی در عملکرد هستههای تنسور اعمال کرده است.
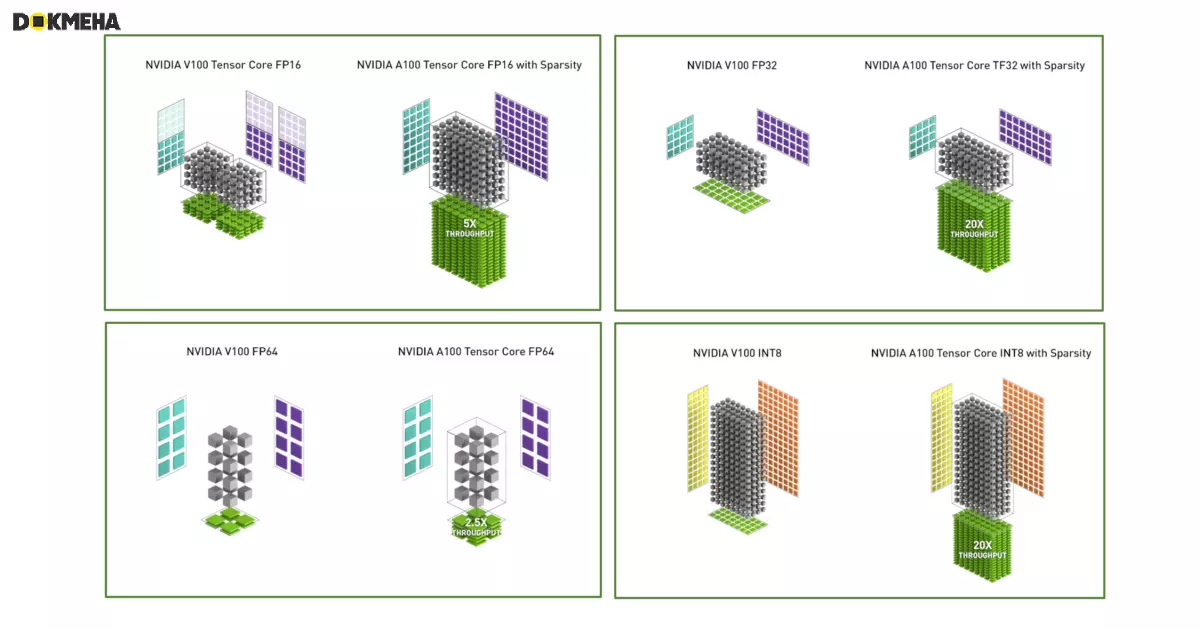
۱. معماری Volta با (V100)
- سال معرفی: 2017
- اولین نسل هستههای تانسور، با قابلیت انجام محاسبات ماتریسی با دقت FP16.
- مناسب برای پردازشهای یادگیری عمیق و شتابدهی به عملیات ماتریسی.
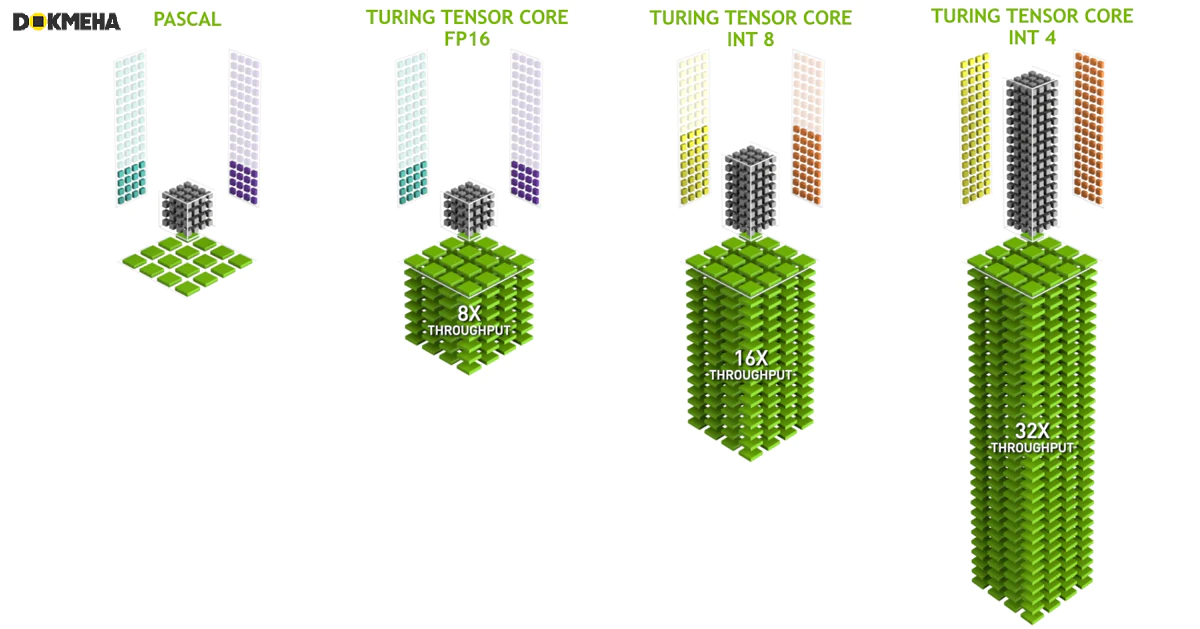
۲. معماری Turing با (T4 / T10 / T40) و (RTX 20 Series)
- سال معرفی: 2018
- هستههای تنسور با پشتیبانی از Mixed Precision (ترکیب FP16 و FP32).
- استفاده در زمان واقعی برای کاربردهایی مانند Ray Tracing و هوش مصنوعی.
۳. معماری Ampere با (A2 / A10 / A16 / A30 / A40 / A100) و (RTX 30 Series)
- سال معرفی: 2020
- FP16 بهبودیافته، همراه با پشتیبانی از دقت جدید TF32 (TensorFloat32) برای محاسبات سریعتر.
- مناسب برای آموزش و استنتاج شبکههای عصبی با کاهش دقت بدون کاهش چشمگیر کیفیت.
۴. معماری Ada Lovelace با (L4 / L40) و (RTX 40 Series)
- سال معرفی: 2022
- عملکرد بهینهتر برای کاربردهای AI Inference و Generative AI.
- پیشرفت در مدیریت حافظه و کاهش مصرف انرژی.
۵. معماری Hopper با (H100 / H200)
- سال معرفی: 2023
- پشتیبانی از FP8 برای کاهش بیشتر حجم دادهها و افزایش سرعت محاسبات.
- تمرکز ویژه بر آموزش مدلهای هوش مصنوعی عظیم مانند مدلهای زبانی بزرگ (LLMs).
هستههای تنسور معماری Hopper (نسل چهارم)
- دقت FP8: افزایش ۶ برابری عملکرد در آموزش مدلهای تریلیون پارامتری نسبت به FP16.
- بهبود کلی عملکرد:
- افزایش ۶۰ برابری عملکرد نسبت به نسلهای اولیه با استفاده از ترکیب دقتهای FP16، FP32، و INT8.
- ایدهآل برای هوش مصنوعی و HPC.
 ۶. معماری Blackwell با (B200)
۶. معماری Blackwell با (B200)
- سال معرفی: 2024 (انتظار میرود)
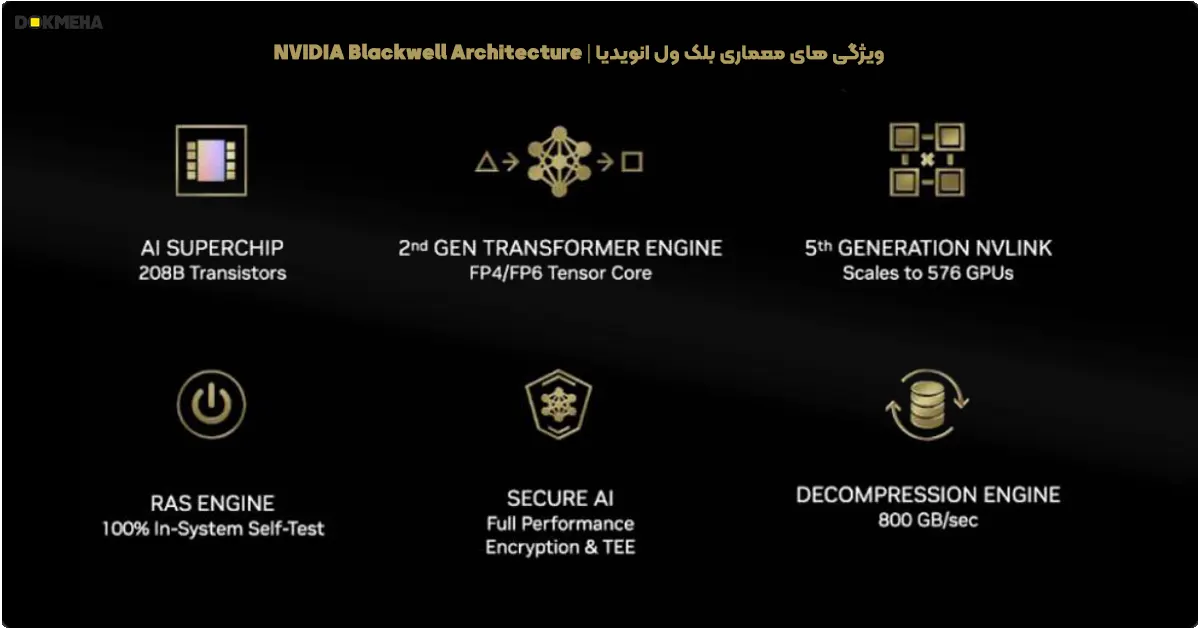
- جدیدترین نسل هستههای تنسور NVIDIA، با تمرکز بر هوش مصنوعی در مقیاس بزرگ و پردازشهای پیچیده.
- ویژگیها: پشتیبانی از دقتهای FP8، FP16، و INT8 برای افزایش سرعت و کاهش مصرف انرژی.
- مزایا: عملکرد بهتر برای آموزش و استنتاج مدلهای عظیم هوش مصنوعی مانند مدلهای زبانی و تصویری.
- موارد استفاده: سرورهای پیشرفته، مراکز داده، و سیستمهای ابری.
هستههای تنسور معماری Blackwell (نسل پنجم)
- افزایش سرعت ۳۰ برابری: نسبت به نسل Hopper برای مدلهای عظیم مانند GPT-MoE-1.8T.
- پشتیبانی از فرمتهای جدید دقت شامل Microscaling Formats، که دقت بهتر و جایگزینی آسانتر با فرمتهای بالاتر را فراهم میکند.
- موتور Transformer نسل دوم:
- فناوری سفارشی Blackwell با استفاده از دقت FP4 عملکرد و بهرهوری را دو برابر کرده است.
- بهینهسازی استنتاج و آموزش مدلهای بزرگ مانند LLMها و MoE.
 تنوع و دستهبندی هستههای تانسور
تنوع و دستهبندی هستههای تانسور
۱. بر اساس معماری
- Volta Tensor Cores (معماری Volta): اولین نسل هستههای تانسور، مناسب برای آموزش مدلهای هوش مصنوعی با دقت FP16.
- Turing Tensor Cores (معماری Turing): پشتیبانی از دقت Mixed Precision (ترکیب FP16 و FP32) برای یادگیری عمیق و Ray Tracing.
- Ampere Tensor Cores (معماری Ampere): بهینهسازی TF32 و FP16 برای آموزش سریعتر و کاهش هزینه محاسبات.
- Ada Tensor Cores (معماری Ada Lovelace): مناسب برای پردازشهای بلادرنگ و کاربردهای گرافیکی پیشرفته مانند Generative AI.
- Hopper Tensor Cores (معماری Hopper): معرفی دقت FP8 برای مدلهای عظیم و تمرکز بر کارایی و مصرف انرژی.
- Blackwell Tensor Cores (معماری Blackwell): بهبود عملکرد برای آموزش مدلهای بزرگتر با کارایی بیشتر و کاهش تأخیر.
۲. بر اساس نوع دقت
- FP32 (Single Precision): برای محاسبات علمی دقیق و مدلهای پیشرفته.
- FP16 (Half Precision): کاهش حجم دادهها و افزایش سرعت پردازش.
- TF32 (Tensor Float 32): ترکیب دقت FP32 و کارایی FP16 برای آموزش سریعتر.
- FP8: جدیدترین دقت برای کاهش حجم دادهها در مدلهای بزرگ.
- INT8 و INT4: برای استنتاج سریع در مدلهای فشرده و کاربردهای محدود منابع.
- BF16 (Brain Float 16): برای حفظ دقت در مدلهای بزرگ در کنار سرعت بالا.
۳. بر اساس کاربرد
- آموزش (Training): طراحی شده برای پردازش حجم بالای داده در مدلهای هوش مصنوعی.
- استنتاج (Inference): کاهش تأخیر و بهینهسازی مصرف انرژی در پیشبینی و اجرا.
- پردازش گرافیکی: استفاده در Ray Tracing و شبیهسازیهای بلادرنگ.
- محاسبات علمی: مناسب برای حل مسائل ریاضی پیچیده و مدلسازی.
- مدلهای زبانی بزرگ (LLMs): شتابدهی به آموزش و استنتاج مدلهایی با میلیاردها پارامتر.
- کاربردهای صنعتی: خودروهای خودران، پردازش تصویر، ویدیو، و اینترنت اشیا (IoT).
چرا Tensor Cores مهم هستند؟
- شتابدهی به یادگیری عمیق: هستههای تانسور، عملیات ضرب ماتریس را چندین برابر سریعتر از هستههای CUDA استاندارد انجام میدهند، که به کاهش زمان آموزش مدلها کمک میکند.
- کارایی در دقت پایین: با معرفی محاسبات دقت پایین (FP16 و FP8)، حجم دادهها و حافظه کاهش مییابد، در حالی که عملکرد مدل حفظ میشود.
- پیشرفت در محاسبات بلادرنگ (Real-Time): از جمله پردازشهای بلادرنگ در گرافیک و استنتاج هوش مصنوعی.
- انعطافپذیری برای مدلهای عظیم: پشتیبانی از مدلهای پیچیده و بزرگ مانند مدلهای زبانی و تصویری پیشرفته.
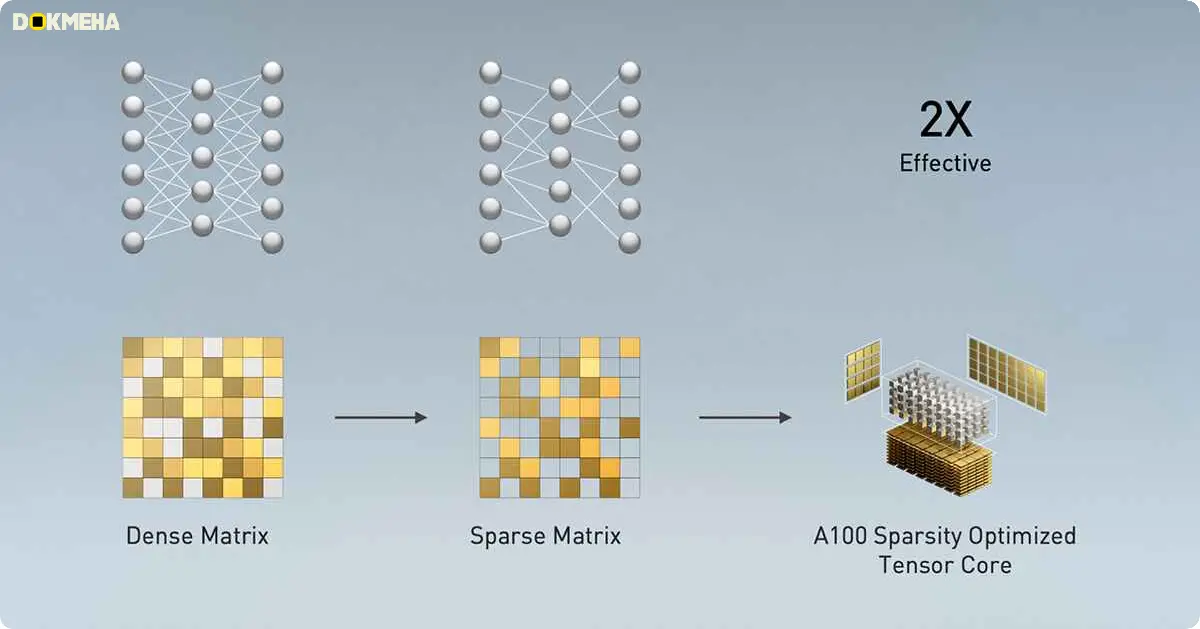
سایر تولیدکنندگان سختافزار با تنسور هستهها
- AMD
- ارائه معماریهایی مانند CDNA برای پردازشهای شتابدهی شده.
- رقابت مستقیم با NVIDIA در شتابدهندههای محاسباتی.
- Google (TPU – Tensor Processing Units):
- پردازندههای مخصوص TensorFlow.
- طراحی شده برای یادگیری عمیق و عملیات مرتبط با هوش مصنوعی.
- Intel (Xeon Phi و AI Accelerators):
- پشتیبانی از یادگیری ماشین و محاسبات تانسوری.
نتیجهگیری
Tensor Cores نقشی حیاتی در تسریع فرآیندهای مرتبط با هوش مصنوعی، یادگیری ماشین، و پردازش گرافیکی پیشرفته دارند. این هستهها با توانایی انجام محاسبات ماتریسی در مقیاس بالا، انقلابی در زمینه پردازش داده و آموزش مدلهای هوش مصنوعی ایجاد کردهاند. با تکامل هر نسل از این هستهها، کاربردهای جدید و بهینهتری برای صنایع مختلف ارائه میشود.