



یادگیری ماشینی (ML) از الگوریتمها و مدلهای آماری استفاده میکند که سیستمهای کامپیوتری را قادر میسازد تا الگوهایی را در مقادیر انبوه داده پیدا کنند و سپس از مدلی استفاده میکند که آن الگوها را شناسایی میکند تا پیشبینی یا توصیفی روی دادههای جدید انجام دهد.
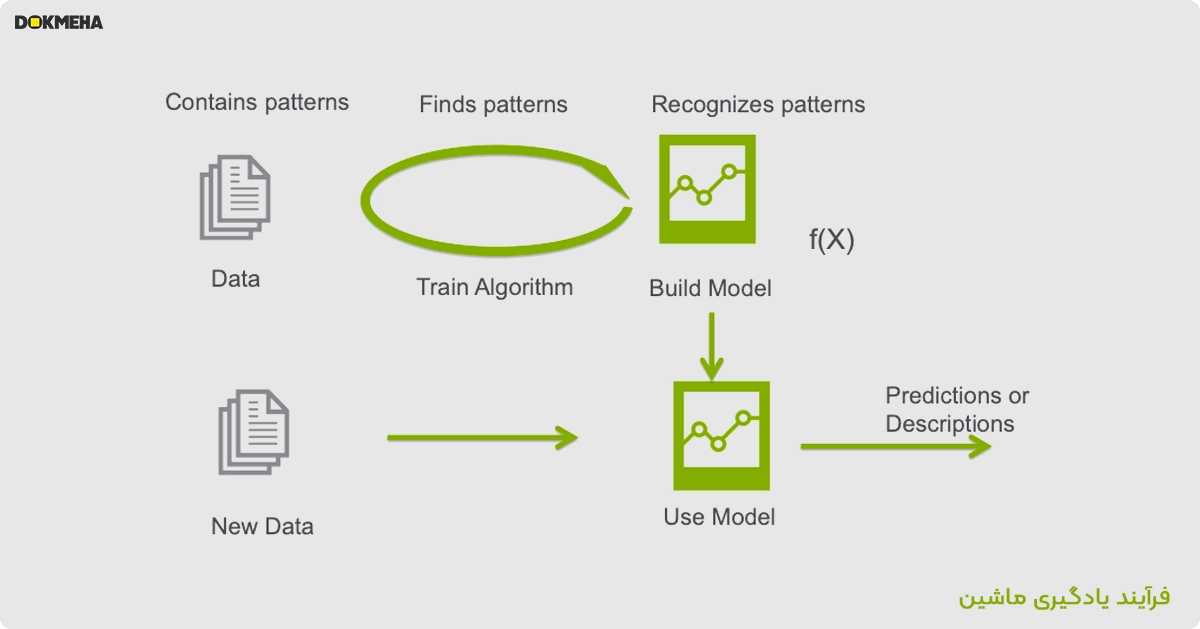
تصویر زیر چرخهای را نشان میدهد که نمایانگر فرآیند یادگیری ماشین است. اجزای کلیدی این چرخه عبارتاند از:
- دادهها (Data): دادهها شامل اطلاعات خامی هستند که حاوی الگوهایی هستند.
- آموزش الگوریتم (Train Algorithm): الگوریتم بر اساس دادههای موجود، الگوها را شناسایی و یاد میگیرد.
- ساخت مدل (Build Model): الگوریتم آموزشدیده تبدیل به مدلی میشود که الگوها را میشناسد و با تابع f(X)f(X) نمایش داده میشود.
- استفاده از مدل (Use Model): مدل آموزشدیده روی دادههای جدید اعمال میشود.
- پیشبینیها یا توصیفات (Predictions or Descriptions): مدل با استفاده از دادههای جدید، پیشبینی یا توصیفی از دادهها ارائه میدهد.
یادگیری ماشینی چیست و چگونه کار می کند؟
به عبارت ساده تر، یادگیری ماشینی یک ماشین را آموزش می دهد تا بدون برنامه ریزی صریح چگونه این کار را انجام دهد. به عنوان زیرمجموعهای از هوش مصنوعی، یادگیری ماشینی در ابتداییترین شکل خود از الگوریتمهایی برای تجزیه دادهها، یادگیری از آنها و سپس پیشبینی یا تصمیمگیری در مورد چیزی در دنیای واقعی استفاده میکند. یادگیری ماشینی از الگوریتمهایی استفاده میکند تا بهطور مستقل مدلهایی را از دادههای وارد شده به پلتفرم یادگیری ماشین ایجاد کند. سیستمهای برنامهریزیشده یا مبتنی بر قانون، دانش یک متخصص را در قوانین برنامهریزی شده جذب میکنند، اما زمانی که دادهها در حال تغییر هستند، بهروزرسانی و نگهداری این قوانین ممکن است دشوار شود. یادگیری ماشینی این مزیت را دارد که میتواند از افزایش حجم دادههای وارد شده به الگوریتمها یاد بگیرد و میتواند پیشبینیهای احتمالی مبتنی بر داده را ارائه دهد. این قابلیت برای استفاده و به کارگیری الگوریتم های بسیار پیچیده برای برنامه های کاربردی داده های بزرگ امروزی به سرعت و به طور موثر یک پیشرفت نسبتا جدید است.
تقریباً هر کار گسسته ای که می تواند با یک الگوی تعریف شده از داده یا با مجموعه ای از قوانین انجام شود، می تواند خودکار شود و بنابراین با استفاده از یادگیری ماشین بسیار کارآمدتر شود. این به شرکتها اجازه میدهد تا فرآیندهایی را که قبلاً توسط انسانها امکانپذیر بود، تغییر دهند، از جمله مسیریابی تماسهای خدمات مشتری و بررسی رزومهها و بسیاری موارد دیگر است. عملکرد یک سیستم یادگیری ماشینی به توانایی تعدادی الگوریتم برای تبدیل یک مجموعه داده به مدل بستگی دارد. الگوریتم های مختلفی برای مسائل و وظایف مختلف مورد نیاز است و حل آنها نیز به کیفیت داده های ورودی و قدرت منابع محاسباتی بستگی دارد.
یادگیری ماشینی از دو تکنیک اصلی استفاده می کند که استفاده از الگوریتم ها را به انواع مختلف تقسیم می کند: نظارت شده، بدون نظارت و ترکیبی از این دو. الگوریتمهای یادگیری تحت نظارت از دادههای برچسبگذاری شده استفاده میکنند، الگوریتمهای یادگیری بدون نظارت الگوهایی را در دادههای بدون برچسب پیدا میکنند، یادگیری نیمه نظارت شده از ترکیبی از داده های برچسب دار و بدون برچسب استفاده می کند، یادگیری تقویتی الگوریتم هایی را برای به حداکثر رساندن پاداش ها بر اساس بازخورد آموزش می دهد.
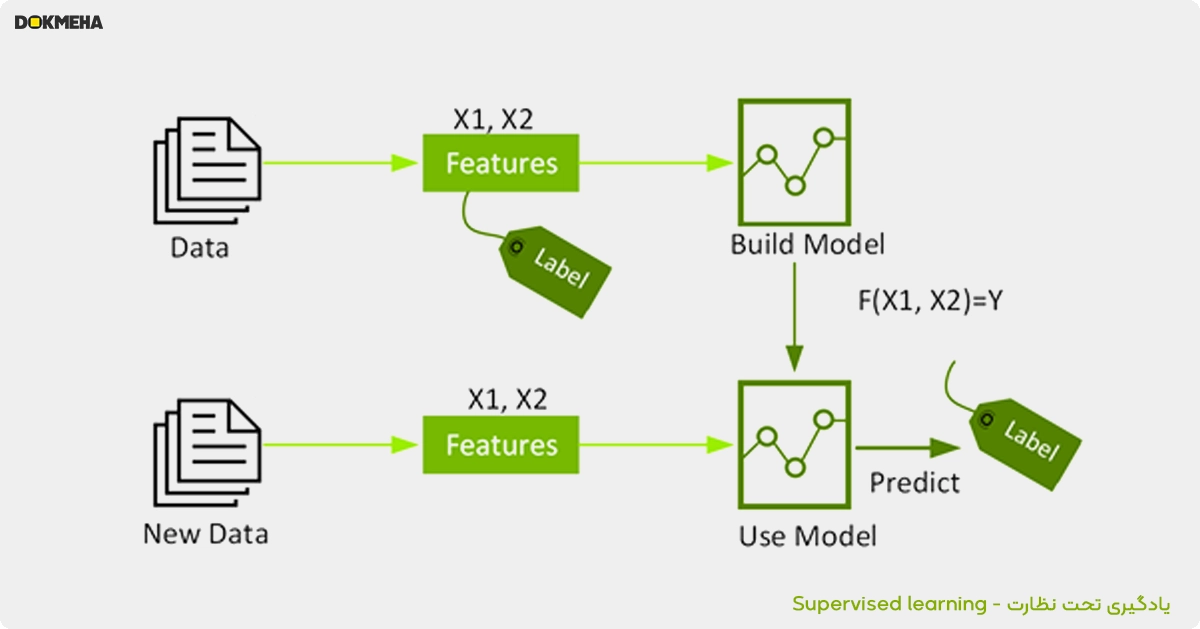
یادگیری تحت نظارت
یادگیری ماشینی تحت نظارت، که به آن تجزیه و تحلیل پیشبینی نیز میگویند، از الگوریتمهایی برای آموزش یک مدل برای یافتن الگوها در یک مجموعه داده با برچسبها و ویژگیها استفاده میکند. سپس از مدل آموزشدیده برای پیشبینی برچسبها بر روی ویژگیهای مجموعه داده جدید استفاده میکند.
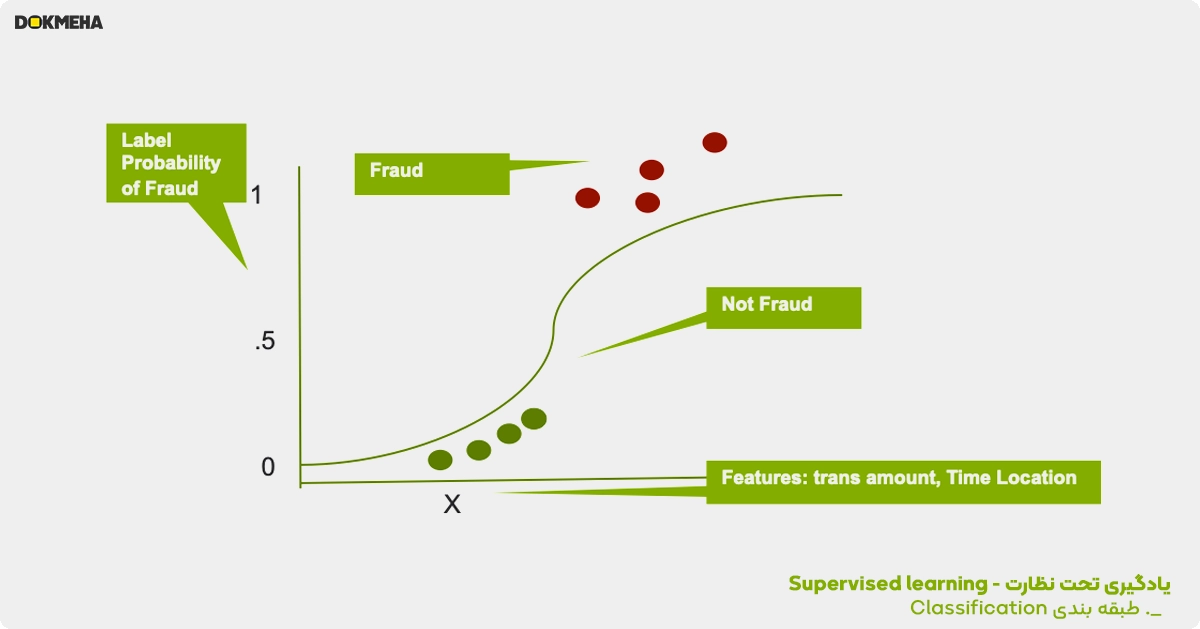
یادگیری تحت نظارت را می توان بیشتر به دو نوع طبقه بندی Classification و رگرسیون Regression تقسیم بندی کرد.
طبقه بندی – Classification
طبقهبندی بر اساس نمونههای برچسبگذاریشده اقلام شناخته شده، مشخص میکند که یک کالا به کدام دسته تعلق دارد. در مثال ساده زیر، رگرسیون لجستیک برای تخمین احتمال تقلبی بودن یا نبودن تراکنش کارت اعتباری (برچسب) بر اساس ویژگیهای تراکنشها (مقدار تراکنش، زمان و مکان آخرین تراکنش) که به عنوان تقلبی شناخته میشوند، استفاده میشود.
نمونه های دیگر طبقه بندی عبارتند از:
- تشخیص هرزنامه
- تحلیل احساسات متنی
- پیش بینی خطر، سپسیس یا سرطان بیمار
رگرسیون – Regression
رگرسیون رابطه بین یک برچسب نتیجه هدف و یک یا چند متغیر ویژگی را برای پیشبینی یک مقدار عددی پیوسته تخمین میزند. در مثال ساده زیر از رگرسیون خطی برای تخمین قیمت خانه (برچسب) بر اساس اندازه خانه (ویژگی) استفاده شده است.
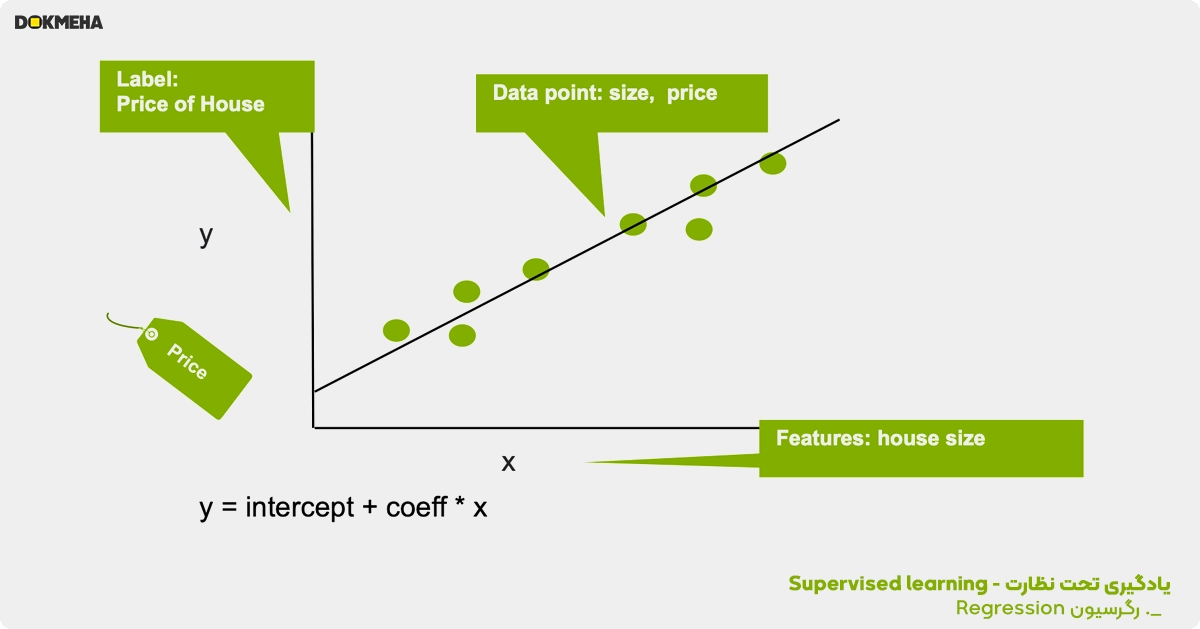
نمونه های دیگر رگرسیون عبارتند از:
- پیش بینی میزان تقلب
- پیش بینی فروش
الگوریتم های یادگیری تحت نظارت عبارتند از:
- رگرسیون لجستیک
- رگرسیون خطی
- ماشین های بردار پشتیبانی
- درختان تصمیم
- جنگل تصادفی
- درختان تصمیم تقویت کننده گرادیان
یادگیری بدون نظارت – Unsupervised learning
یادگیری بدون نظارت، که تجزیه و تحلیل توصیفی نیز نامیده میشود، دادههای برچسبگذاریشدهای از قبل ارائه نشده است و میتواند به دانشمندان داده در یافتن الگوهای ناشناخته قبلی در دادهها کمک کند. این الگوریتمها تلاش میکنند تا ساختار ذاتی دادههای ورودی را یاد بگیرند، شباهتها یا قاعدهمندیها را کشف کنند. کارهای رایج بدون نظارت شامل خوشه بندی و ارتباط است.
خوشه بندی – Clustering
در خوشهبندی، یک الگوریتم ورودیها را با تجزیه و تحلیل شباهتهای بین نمونههای ورودی، به دستههایی طبقهبندی میکند. نمونهای از خوشهبندی شرکتی است که میخواهد مشتریان خود را به منظور تنظیم بهتر محصولات و پیشنهادات تقسیم کند. مشتریان را می توان بر اساس ویژگی هایی مانند جمعیت شناسی و تاریخچه خرید گروه بندی کرد. خوشهبندی با یادگیری بدون نظارت اغلب با یادگیری نظارت شده ترکیب میشود تا نتایج ارزشمندتری به دست آید.
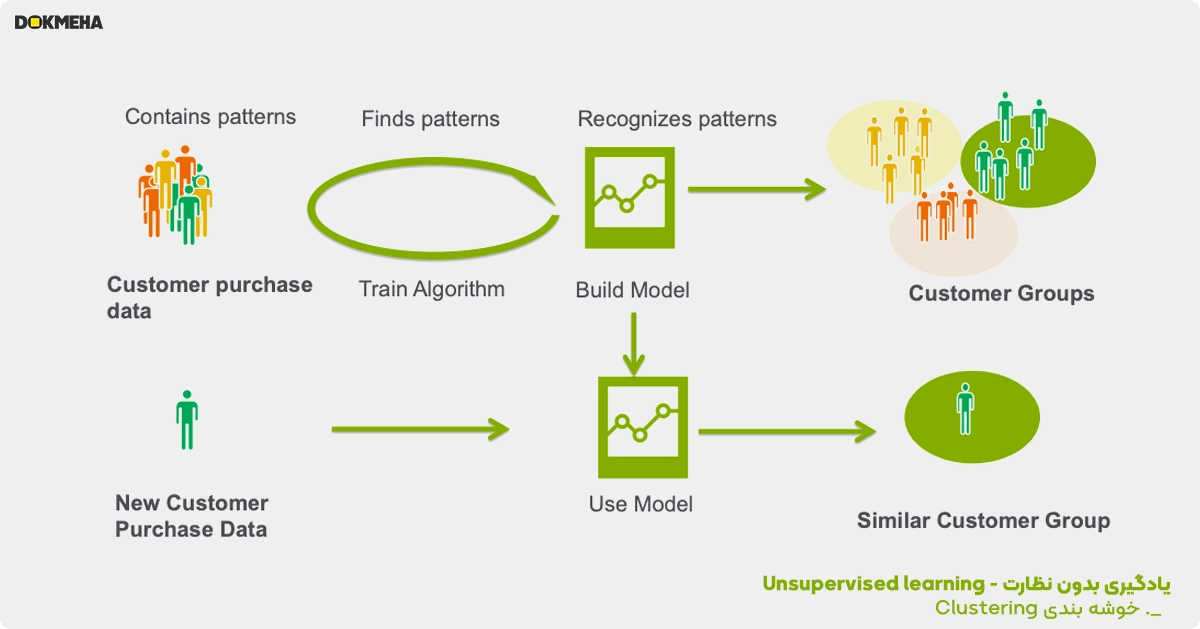
سایر نمونه های خوشه بندی عبارتند از:
- گروه بندی نتایج جستجو
- گروه بندی بیماران مشابه
- دسته بندی متن
- تشخیص ناهنجاری (پیدا کردن چیزی که مشابه نیست، به معنای نقاط پرت از خوشه ها)
یادگیری انجمنی – Association learning
ارتباط یا الگوکاوی مکرر در مجموعههای بزرگی از اقلام داده، تداعیهای مکرر همزمان (روابط، وابستگیها) را پیدا میکند. نمونه ای از انجمن های مشترک محصولاتی است که اغلب با هم خریداری می شوند، مانند داستان معروف آبجو و پوشک. تجزیه و تحلیل رفتار خریداران مواد غذایی نشان داد که مردانی که پوشک می خرند اغلب آبجو نیز می خرند.
الگوریتم های یادگیری بدون نظارت عبارتند از:
- تخصیص دیریکله نهفته (LDA)
- مدل مخلوط گاوسی (GMM)
- حداقل مربعات متناوب (ALS)
مزایای یادگیری ماشینی
مزایای یادگیری ماشین برای تجارت متنوع و گسترده است و می تواند شامل موارد زیر باشد:
- پیش بینی تجزیه و تحلیل سریع و پردازش به موقع و به اندازه کافی به کسب و کارها اجازه می دهد تا تصمیمات سریع و مبتنی بر داده اتخاذ کنند.
- تسهیل پیشبینیها و تشخیصهای پزشکی دقیق با شناسایی سریع بیماران در معرض خطر، توصیه طیف وسیعی از داروها و پیشبینی بستری مجدد
- سادهسازی مستندات زمانبر در ورود دادهها با کاهش قابلتوجه خطاهای ناشی از تکرار دادهها و سایر نادرستیها در حالی که کارگران را از سختی وارد کردن دادهها رها میکند.
- بهبود دقت قوانین و مدل های مالی برای تقویت مدیریت پرتفوی؛ فعال کردن تجارت الگوریتمی، پذیره نویسی وام، و مهمتر از همه افزایش کشف تقلب
- افزایش کارایی تعمیر و نگهداری پیش بینی شده با ایجاد برنامه های تعمیر و نگهداری کارآمد و پیش بینی کننده
- بهبود بخشبندی مشتری و پیشبینی ارزش طول عمر، دادن اطلاعات ارزشمند به بازاریابان برای بهینهسازی سرنخها، به حداکثر رساندن ترافیک وب و افزایش بازده از کمپینهای پستی و ایمیلی.
موارد استفاده از یادگیری ماشین
محاسبات تسریع شده و یادگیری ماشین در حال تقویت محاسبات هوشمند برای حوزه بهداشت و درمان هستند. با یک پلتفرم برای تصویربرداری، ژنومیک، پایش بیماران و کشف دارو—که در هر مکانی، از دستگاههای تعبیهشده گرفته تا لبه و هر کلاود، قابل پیادهسازی است— پلتفرم NVIDIA Clara صنعت بهداشت و درمان را قادر میسازد که نوآوری کند و مسیر دستیابی به پزشکی دقیق را تسریع بخشد.
خردهفروشان پیشرو از یادگیری ماشین برای کاهش ضایعات، بهبود پیشبینیها، خودکارسازی لجستیک انبار، تعیین تبلیغات درونفروشگاهی و قیمتگذاری بلادرنگ، ارائه شخصیسازی و توصیههای مشتری و ارتقای تجربه خرید—چه در فروشگاهها و چه آنلاین—استفاده میکنند.
درک رفتار مصرفکننده برای خردهفروشان هیچگاه به این اندازه حیاتی نبوده است. برای رشد کسبوکار، توصیههای هوشمندانه برای بازاریابی شخصیسازیشده استفاده میشوند. برای افزایش درآمد، خردهفروشان آنلاین از الگوریتمهای یادگیری ماشین (ML) و یادگیری عمیق (DL) با قدرت پردازش گرافیکی برای ارائه سریعتر و دقیقتر موتورهای توصیه استفاده میکنند. تاریخچه خرید و فعالیتهای کاربران در وب، دادههایی را برای تحلیل مدلهای یادگیری ماشین فراهم میکند که توصیهها را تولید کرده و از تلاشهای خردهفروشان برای فروش بیشتر پشتیبانی میکند.
مؤسسات مالی در حال پذیرش یادگیری ماشین برای ارائه خدمات هوشمندتر و ایمنتر هستند. راهکارهای یادگیری ماشین با قدرت پردازشی GPU میتوانند در میان حجم عظیمی از دادهها، بینشهای کلیدی را شناسایی کرده، وظایف روتین را از کارکنان با خودکارسازی کم کنند، محاسبات ریسک و تشخیص تقلب را تسریع کنند و خدمات مشتری را با سیستمهای توصیهگر دقیقتر بهبود بخشند.
NVIDIA مدلهای از پیش آموزشدیده و راهکارهای نرمافزاری ارائه میدهد که کاربردهای یادگیری ماشین را بسیار سادهتر میکند. به عنوان مثال، پلتفرم NVIDIA Metropolis به توسعهدهندگان کمک میکند تا برنامههای یادگیری ماشین برای بهبود مدیریت موجودی خردهفروشی، ارتقای تلاشهای جلوگیری از خسارت، و سادهسازی تجربه پرداخت برای مصرفکنندگان ایجاد کنند.
به عنوان نمونهای عملی، Walmart از فناوری NVIDIA برای مدیریت جریان کاری کارکنان و اطمینان از تازگی گوشت و محصولات در برخی از فروشگاهها استفاده میکند. همچنین، BMW از راهکارهای هوش مصنوعی لبه NVIDIA برای خودکارسازی بازرسیهای نوری در تأسیسات تولیدی خود بهره میبرد. در همین حال، China Mobile، که بزرگترین شبکه بیسیم جهان را مدیریت میکند، از پلتفرم NVIDIA برای ارائه قابلیتهای هوش مصنوعی از طریق شبکههای 5G استفاده میکند.
چرا یادگیری ماشین برای شما اهمیت دارد؟
شرکتها روزبهروز بیشتر به دادهمحوری روی میآورند—آنها دادههای بازار و محیط را جمعآوری کرده و از تحلیلها و یادگیری ماشین برای شناسایی الگوهای پیچیده، تشخیص تغییرات و انجام پیشبینیهایی استفاده میکنند که بهطور مستقیم بر سودآوری آنها تأثیر میگذارد. شرکتهای دادهمحور از علم داده برای مدیریت و درک حجم عظیمی از دادهها بهره میبرند.
علم داده در هر صنعتی نقش دارد. شرکتهای بزرگ در حوزههایی همچون خردهفروشی، مالی، بهداشت و درمان و لجستیک از فناوریهای علم داده برای بهبود رقابتپذیری، پاسخگویی و کارایی خود استفاده میکنند. شرکتهای تبلیغاتی از آن برای هدفگذاری مؤثرتر تبلیغات بهره میگیرند. شرکتهای وامدهنده از آن برای پیشبینی دقیقتر ریسک نکول و دستیابی به حداکثر بازدهی استفاده میکنند. خردهفروشان نیز با استفاده از علم داده، زنجیره تأمین خود را بهینه میسازند. در واقع، دسترسی به نرمافزارهای تحلیل داده و یادگیری ماشین در مقیاس بزرگ و متنباز، نظیر Hadoop، NumPy، scikit-learn، Pandas و Spark در میانه دهه ۲۰۰۰ میلادی، انقلاب دادههای کلان را آغاز کرد.
امروزه علم داده و یادگیری ماشین به بزرگترین بخش محاسبات در جهان تبدیل شدهاند. بهبودهای جزئی در دقت مدلهای پیشبینی یادگیری ماشین میتوانند میلیاردها دلار برای شرکتها سودآوری داشته باشند. آموزش مدلهای پیشبینی در هسته اصلی علم داده قرار دارد. در واقع، بخش عمدهای از بودجههای فناوری اطلاعات برای علم داده صرف ساخت مدلهای یادگیری ماشین میشود که شامل تبدیل دادهها، مهندسی ویژگیها، آموزش، ارزیابی و مصورسازی است. برای ساخت بهترین مدلها، دانشمندان داده باید مدلهای خود را بارها و بارها آموزش، ارزیابی و بازآموزی کنند. امروزه این تکرارها چندین روز زمان میبرند و تعداد آنها را پیش از استقرار در تولید محدود میکنند که بر کیفیت نتیجه نهایی تأثیر میگذارد.
اجرای تحلیلها و یادگیری ماشین در سطح سازمانها به زیرساختهای عظیمی نیاز دارد. شرکتهای Fortune 500 با گسترش مقیاس محاسباتی خود و سرمایهگذاری در هزاران سرور CPU، خوشههای بزرگ علم داده ایجاد میکنند. با این حال، گسترش مقیاس با استفاده از CPU دیگر کارآمد نیست. در حالی که حجم دادههای جهان هر سال دو برابر میشود، محاسبات مبتنی بر CPU به بنبست خوردهاند، چراکه قانون مور دیگر پاسخگوی نیازها نیست. معماری موازی گسترده GPU که شامل هزاران هسته کوچک و کارآمد است و برای انجام وظایف متعدد به طور همزمان طراحی شده، میتواند راهحل باشد. همانطور که محاسبات علمی و یادگیری عمیق به شتابدهی GPU روی آوردهاند، تحلیل دادهها و یادگیری ماشین نیز از موازیسازی و شتابدهی GPU بهرهمند خواهند شد.
چرا یادگیری ماشین از GPUها بهره میبرد؟
NVIDIA پلتفرم RAPIDS را توسعه داده است—یک پلتفرم متنباز برای شتابدهی تحلیل داده و یادگیری ماشین—که امکان اجرای کامل خطوط آموزشی علم داده را بهطور سرتاسری در GPUها فراهم میکند. این پلتفرم بر اساس ابتداییترین عملیات محاسباتی NVIDIA CUDA برای بهینهسازی در سطح پایین طراحی شده، اما آن موازیسازی GPU و پهنای باند بالای حافظه را از طریق رابطهای کاربرپسند پایتون در دسترس قرار میدهد.
دادههای مورد استفاده توسط کتابخانههای RAPIDS بهطور کامل در حافظه GPU ذخیره میشوند. این کتابخانهها به دادهها با استفاده از حافظه مشترک GPU و در قالب دادهای بهینهشده برای تحلیل—Apache Arrow™—دسترسی دارند. این رویکرد نیاز به انتقال داده بین کتابخانههای مختلف را از بین میبرد و همچنین امکان همکاری با نرمافزارهای استاندارد علم داده و ورود داده از طریق APIهای Arrow را فراهم میکند. اجرای کامل گردشکار علم داده در حافظه پرسرعت GPU و موازیسازی بارگذاری داده، دستکاری داده و الگوریتمهای یادگیری ماشین روی هستههای GPU، منجر به ۵۰ برابر سرعت بیشتر در گردشکارهای علم داده میشود.
RAPIDS با تمرکز بر وظایف رایج آمادهسازی داده برای تحلیل و علم داده، یک API آشنا بهصورت DataFrame ارائه میدهد که با scikit-learn و مجموعه متنوعی از الگوریتمهای یادگیری ماشین ادغام شده، بدون اینکه هزینههای معمول سریالسازی را تحمیل کند. این ویژگی امکان شتابدهی به خطوط پردازش سرتاسری را فراهم میکند—از آمادهسازی داده تا یادگیری ماشین و یادگیری عمیق (DL). علاوه بر این، RAPIDS از پیادهسازیهای چند نود و چند GPU پشتیبانی میکند، که پردازش و آموزش بر روی مجموعه دادههای بسیار بزرگتر را با شتابی چشمگیر ممکن میسازد.
اجزای RAPIDS:
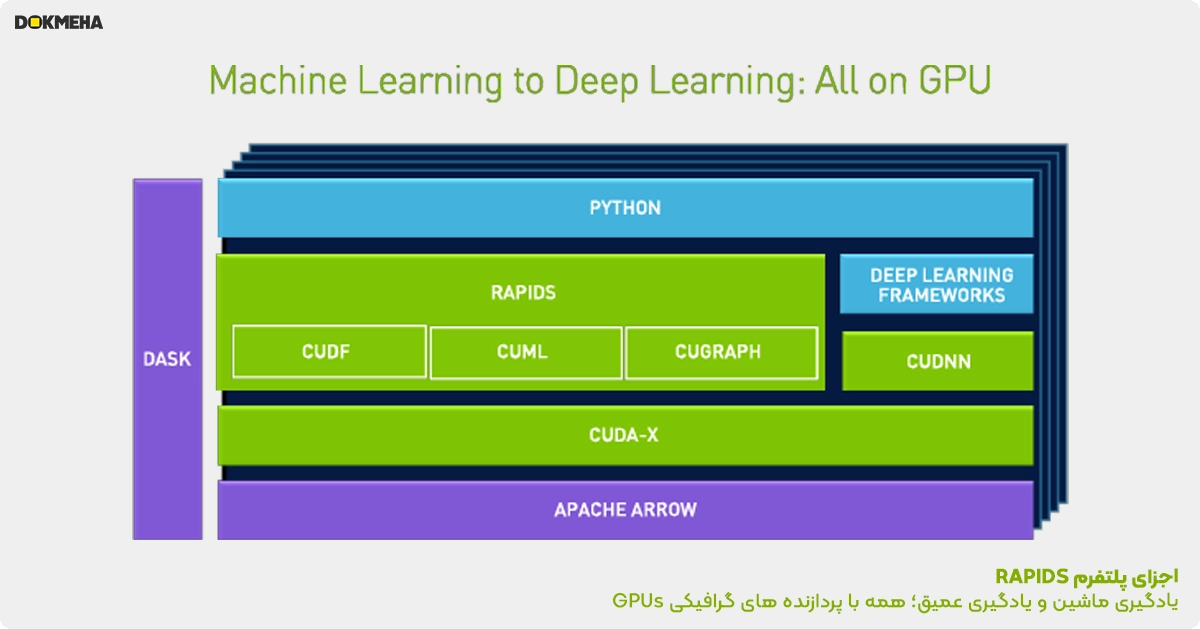
- DataFrame – cuDF:
این کتابخانه برای دستکاری دیتافریمها طراحی شده و از شتاب GPU بهره میبرد. cuDF بر پایه Apache Arrow ساخته شده و مدیریت داده برای آموزش مدلها را امکانپذیر میکند. نسخه پایتون این کتابخانه که از هستههای شتابیافته CUDA C++ استفاده میکند، API مشابه pandas ارائه میدهد و انتقال از pandas به cuDF را بهآسانی ممکن میسازد. - کتابخانههای یادگیری ماشین – cuML:
مجموعهای از کتابخانههای یادگیری ماشین شتابیافته با GPU است که نسخههای GPU تمامی الگوریتمهای موجود در scikit-learn را ارائه میدهد. - کتابخانههای تحلیل گراف – cuGRAPH:
این مجموعه از کتابخانههای تحلیل گراف بهطور یکپارچه با مجموعه نرمافزاری علم داده RAPIDS ادغام میشود. - کتابخانههای یادگیری عمیق:
RAPIDS از رابط آرایه CUDA (CUDA array_interface) و DLPak بهصورت بومی پشتیبانی میکند. این ویژگی امکان انتقال مستقیم دادههای ذخیرهشده در Apache Arrow به فریمورکهای یادگیری عمیق مانند TensorFlow، PyTorch و MxNet را فراهم میسازد. - کتابخانههای مصورسازی:
RAPIDS شامل کتابخانههای مصورسازی داده است که بر اساس Apache Arrow طراحی شدهاند. فرمت داده درونحافظهای GPU، مصورسازی داده با عملکرد بالا و نرخ فریم (FPS) بالا را حتی با مجموعه دادههای بسیار بزرگ ممکن میسازد.
سرعت بخشیدن به Apache Spark 3.0 با GPU و RAPIDS
با رشد روزافزون استفاده از یادگیری ماشین (ML) و یادگیری عمیق (DL) برای مجموعه دادههای بزرگ، Spark به یکی از ابزارهای محبوب برای پیشپردازش دادهها تبدیل شده است. این فرآیند، دادههای خام را برای استفاده در مدلهای یادگیری ماشین آماده میکند.
پلتفرم RAPIDS با بهرهگیری از GPUها، فرآیند پیشپردازش داده در Spark 3.0 را بهشدت تسریع میبخشد. شتاب GPU در عملیات سنگین مانند فیلتر کردن دادهها، گروهبندی، و تبدیلات داده کمک میکند تا زمان اجرای تحلیلها و آمادهسازی داده کاهش یابد و کارایی بهبود پیدا کند. این ویژگی به دانشمندان داده و مهندسان یادگیری ماشین این امکان را میدهد که مدلهای خود را سریعتر آموزش دهند و از منابع محاسباتی بهینهتر استفاده کنند.
مزایای استفاده از RAPIDS با Spark 3.0:
- پردازش موازی در مقیاس بالا به کمک معماری GPU.
- کاهش زمان لازم برای آمادهسازی دادههای بزرگ.
- سازگاری با APIهای موجود در Spark برای مهاجرت آسان.
- امکان اجرای خطوط یادگیری ماشین و یادگیری عمیق بهصورت یکپارچه.
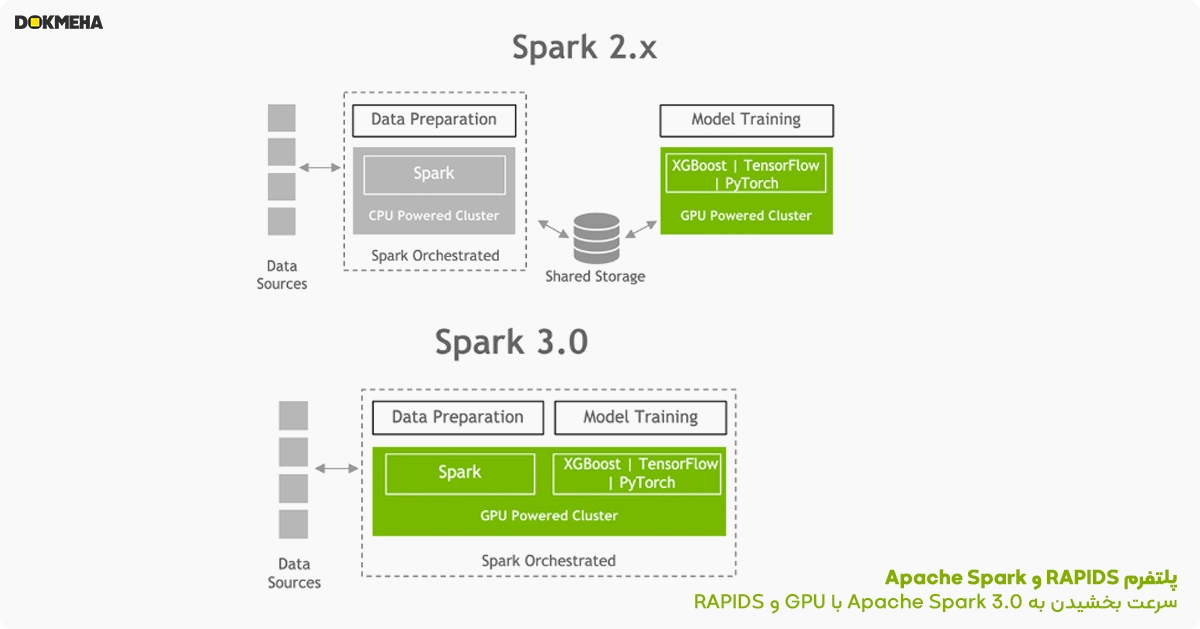
NVIDIA با همکاری جامعه Apache Spark، GPUها را به پردازش بومی Spark وارد کرده است. با انتشار Apache Spark 3.0 و معرفی شتابدهنده RAPIDS برای Apache Spark، اکنون امکان ایجاد یک خط پردازش یکپارچه وجود دارد. این خط شامل تمامی مراحل ورود دادهها (Data Ingestion)، آمادهسازی دادهها (Data Preparation)، آموزش مدل (Model Training) و تنظیم مدل (Model Tuning) است و تمامی این مراحل میتوانند بر روی یک خوشه شتابیافته با GPU انجام شوند.
مزایا:
- رفع گلوگاهها: GPUها با پردازش موازی حجم زیادی از دادهها به کاهش تأخیر و افزایش بهرهوری کمک میکنند.
- افزایش عملکرد: شتابدهی GPU باعث میشود فرآیندها سریعتر اجرا شوند و زمان اجرای خطوط داده کاهش یابد.
- سادهسازی خوشهها: استفاده از GPUها پیچیدگیهای مرتبط با مدیریت خوشهها را کاهش میدهد و منابع را بهینه میکند.
این راهکار، قدرت GPUها را در کنار انعطافپذیری و مقیاسپذیری Spark فراهم میکند و یک تحول بزرگ در مدیریت و تحلیل دادههای بزرگ به وجود آورده است.